Data Generation Workflows
Contents
Data Generation Workflows#
Workflows are a great way to interact with the Infinity system. Workflows allow users to
Craft a synthetic data batch
Submit the batch for cloud execution
Download the resulting synthetic data to a local computer
Workflows also allow for convenient recordkeeping. Your past submissions are present in Jupyter notebooks that you can later reference or reuse.
We’ll start with a workflow example, then discuss key concepts in more detail.
Example#
In this section, we’ll generate our first batch of synthetic data. Make sure you have already completed the infinity-workflows installation.
1. Create a Workflow Notebook#
Launch the jupyter notebook environment if you haven’t already
./run_notebooks.sh
Open the visionfit/create_a_workflow.ipynb and execute the cells.
Select
Submit Batchand input your Infinity API token.Click
Get Generatorsand selectvisionfit-flagship-v0.1.0.Click
Create Notebook.Click the generated link to go to the Submit Batch notebook that was created.
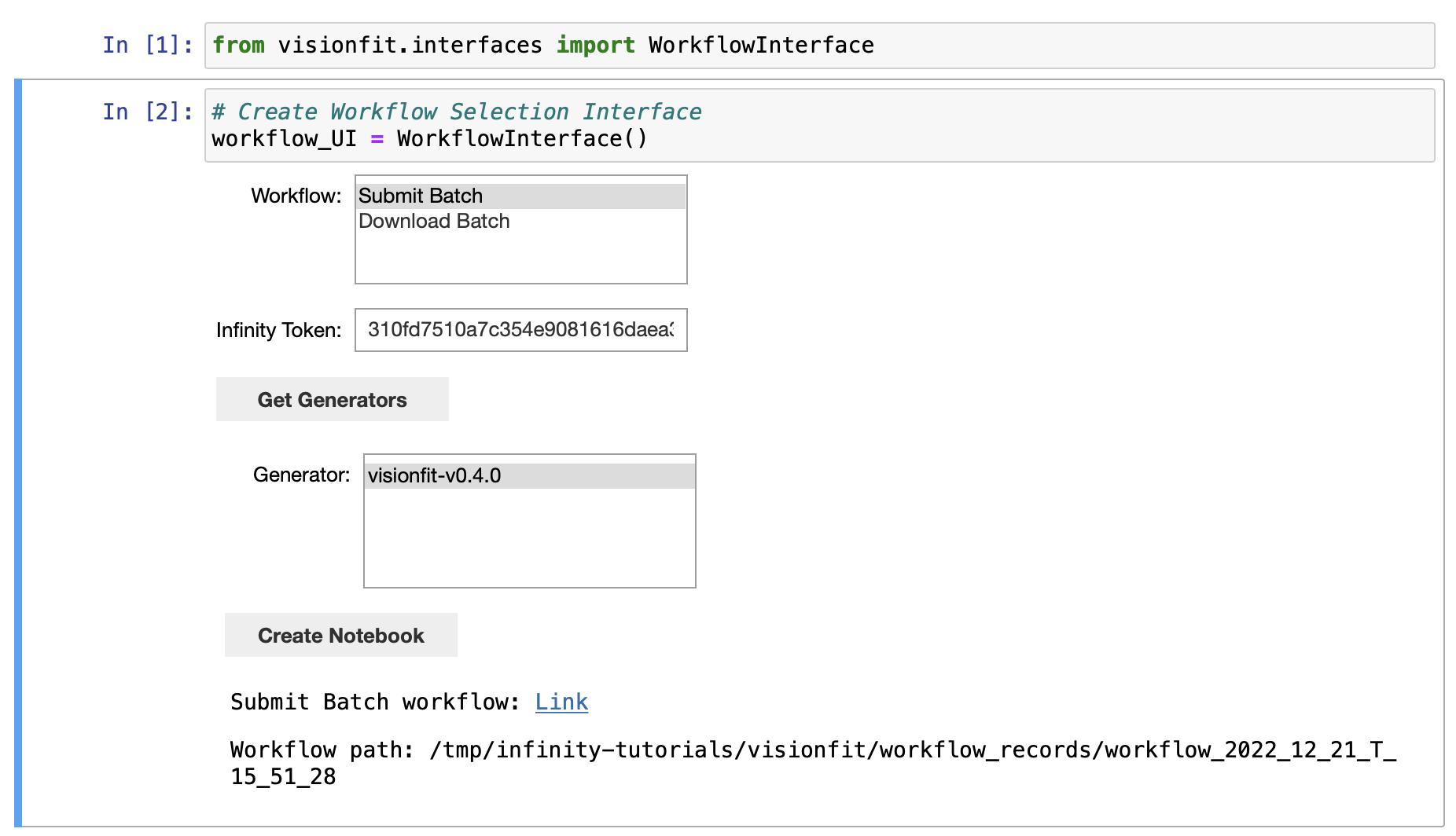
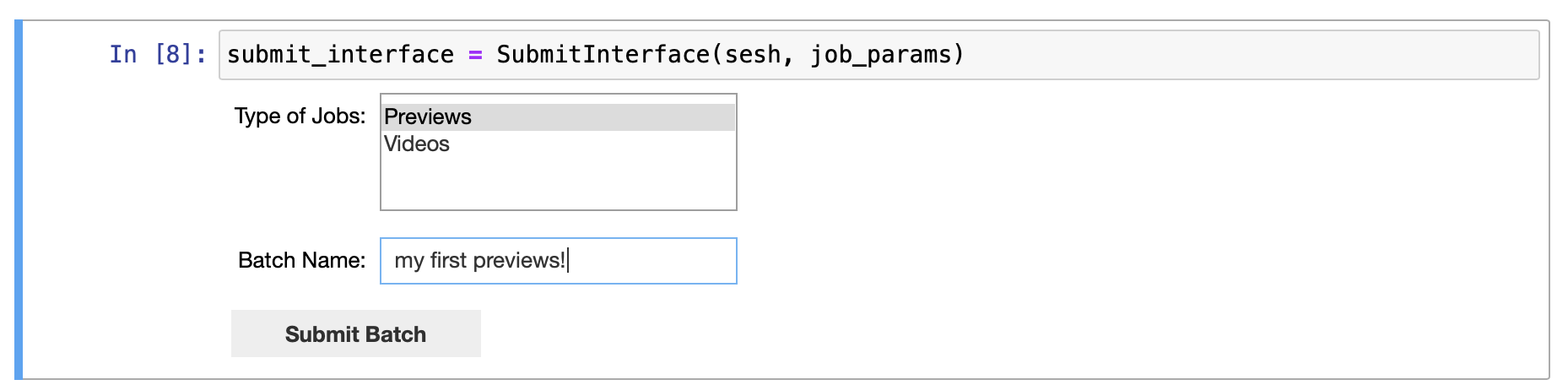
2. Submit a Batch#
In the Submit Batch notebook
Run the cells to create a set of job parameters.
Select that you want a batch of
Previews(single frames for each job).Give the batch a name, such as
my first previews!.Click Confirm Submission to start running the batch in the cloud.
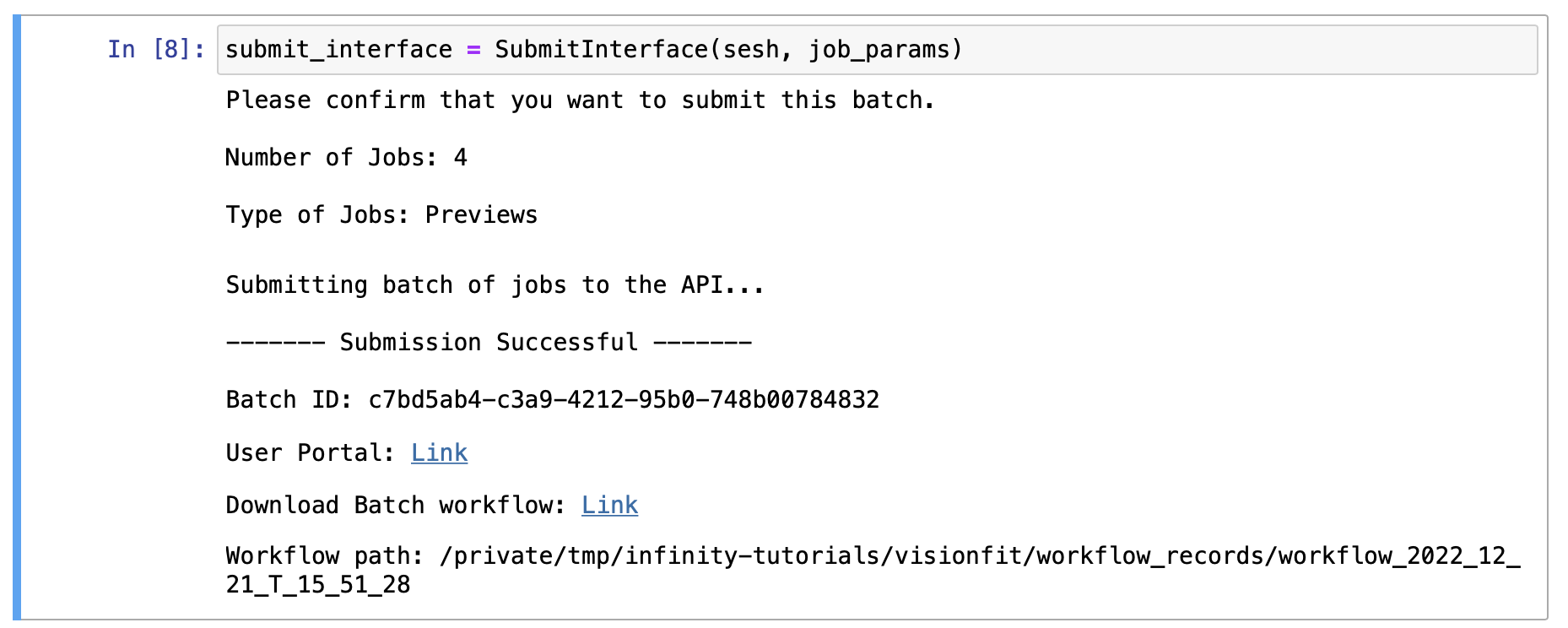
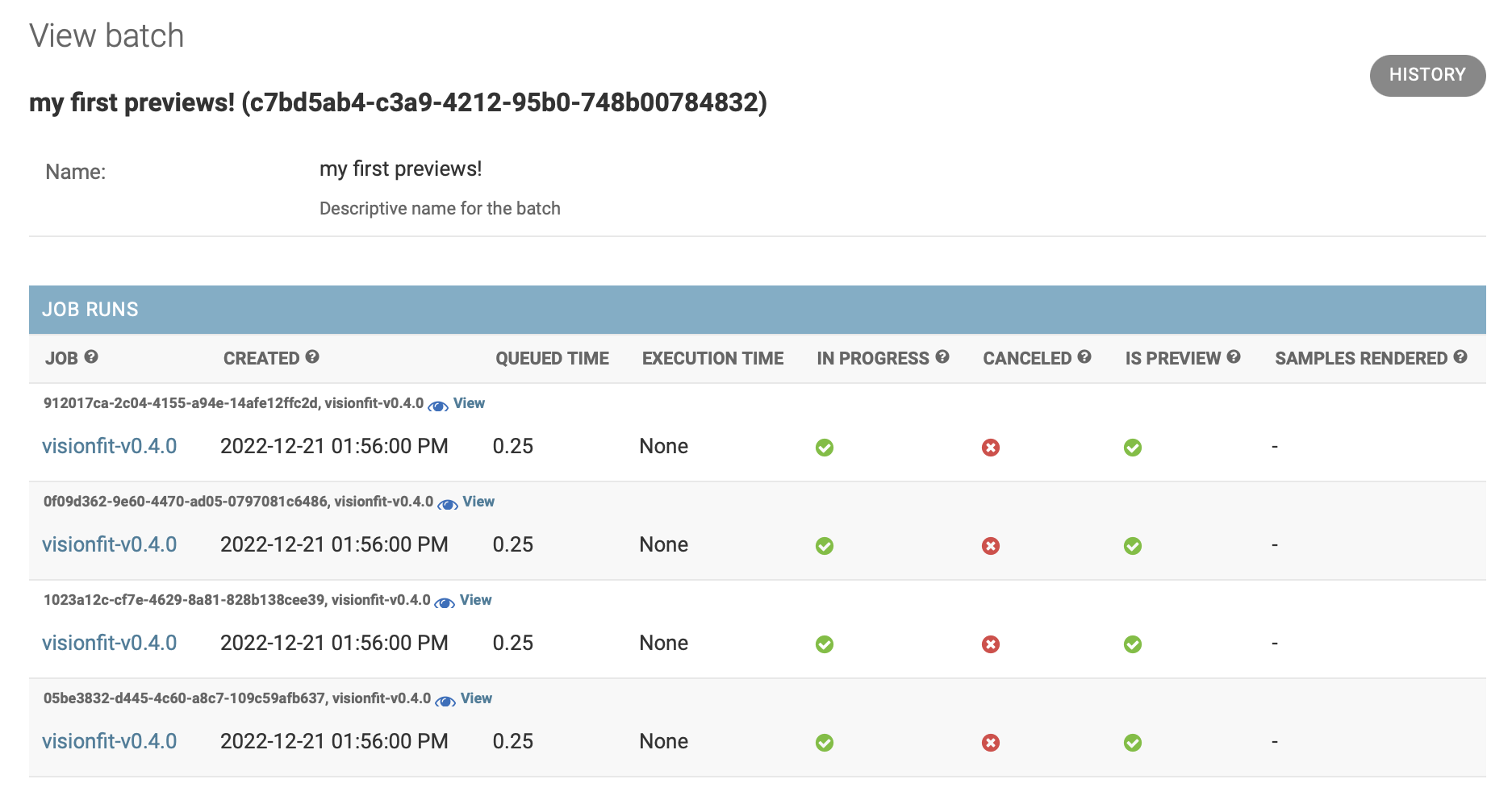
3. Review API User Portal#
Upon submission of a batch, a link to the API User Portal is generated and displayed. Follow the link and log in with your email and password if necessary.
You’ll see information about the status of the jobs in your batch.
Note
You have to refresh the page to see updated job status information. Jobs are done when they are no longer “In progress.”
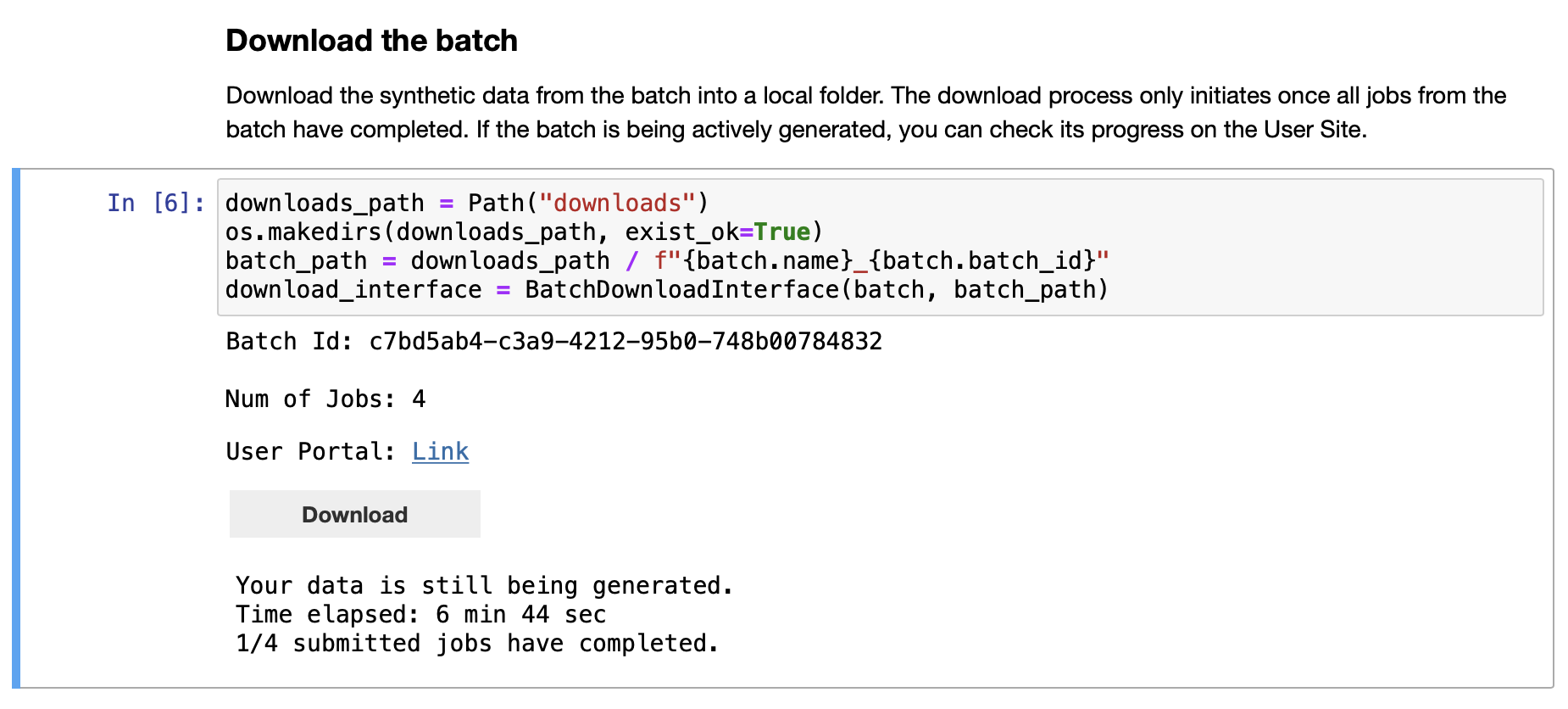
4. Download the Batch#
Return to the submission notebook and follow the link to the generated Download Batch notebook.
Execute the notebook to download and view your data
Run the cells until you reach the “Download Batch” section.
Click
Downloadto check the status of the jobs and download them once they’re complete. You may have to press this button multiple times until jobs have completed (we’ll later introduce a programmatic means to poll batch completion).Run the remaining cells to view your synthetic frames and their parameter distributions.
Workflow Concepts#
Now that we have run through a simple workflow, we’ll introduce key workflow concepts. In particular, we’ll discuss how workflow notebooks act as saved reports, the difference between previews and videos, and how to generate data with specific distributions of parameters.
Workflows are Saved Reports#
Each time you wish to create a batch of synthetic data jobs, you can always start from the visionfit/create_a_workflow.ipynb notebook. This notebook creates a Submit notebook, saved in the visionfit/workflow_records/workflow_<YYYY>_<MM>_<DD>_T_<HH>_<MM>_<SS> directory of infinity-workflows. The Submit notebook walks you through submission of a batch and generates a Download notebook for that batch, saved in the same directory.
Accordingly, workflow notebooks serve as saved reports of the work you have performed to generate and review synthetic data.
If you want to submit a new batch with slightly different parameters, you can easily replicate and modify a Submission notebook, which will ultimately generate a new Download notebook.
Additionally, saved reports facilitate a very common use case:
You create and submit several batches, many of which are large and will take a long time to render.
You return to the Download notebooks the next day to download and review the results of the batches rendered.
Previews vs Videos#
When executing a Submission notebook, you must specify if you wish to generate previews or videos. If previews are selected, a single frame will be generated by each job, independent of the parameters specified. Previews are inherently faster to render and thus can be used to screen the results of selecting specific parameters before kicking off large video rendering jobs.
Specifying Parameters#
Defining parameter distributions is how you obtain synthetic data that meets your specs.
Important
You can always view the generator pages in the API User Portal for detailed parameter information, including parameter names, descriptions, and constraints.
In the following examples, we will be referring to job parameters for the VisionFit Flagship 0.1.0 generator.
Key Concepts#
Some key concepts are important to define explicitly and provide a good mental model before we continue.
A generator is the fundamental unit of synthetic data generation. Each is a program that executes in our cloud compute clusters and is parameterized with a concrete set of input parameters, or job parameters. With a single set of concrete job parameters, we can run a single job. In our Python front-end, the job parameters for a single job are defined in a dictionary like below:
single_job = {
"scene": "BEDROOM_2",
"exercise": "UPPERCUT-LEFT",
"gender": "FEMALE",
"num_reps": 1,
"camera_distance": 3.3,
"add_wall_art": True,
"frame_rate": 30,
}
A collection of one or more concrete jobs (set of job parameters) is used to define and submit a batch. The batch is the fundamental unit of synthetic data submission with many abstractions and tools build around this concept. The set of jobs that constitute a batch is defined as a list of dictionaries:
job_params = [
{
"scene": "BEDROOM_2",
"exercise": "UPPERCUT-LEFT",
"gender": "FEMALE",
"num_reps": 1,
"camera_distance": 3.3,
"add_wall_art": True,
"frame_rate": 30,
},
{
"scene": "GYM_1",
"exercise": "UPPERCUT-RIGHT",
"gender": "MALE",
"num_reps": 2,
"camera_distance": 2.5,
"add_wall_art": False,
"frame_rate": 12,
}]
To submit a single job, simply construct a single element list.
Use fixed default parameters#
Here is an example of constructing a dictionary of job parameters for 10 total jobs, each with 1 repetition of the uppercut exercise:
job_params = [{"num_reps": 1, "exercise": "UPPERCUT-LEFT"} for _ in range(10)]
This job_params list can be directly submitted to the cloud API. All unspecified parameters will receive the default value specified in the generator’s documentation upon submission. This is probably not what you want. Instead, often you will want unspecified parameters to be sampled in some way (e.g., randomly).
Use randomly sampled parameters#
We provide the sample_input function (available as a function in the visionfit.utils.sampling module of the workflows repository) as a convenient way to specify values for parameters you explicitly care about while letting the rest of the parameters be chosen randomly. The random sampling is tailored for each parameter. Note that this sample_input function is specific the to visionfit class of generators.
job_params = [
sample_input(sesh=sesh, num_reps=1, exercise="UPPERCUT-LEFT") for _ in range(10)
]
Here we have specified values for num_reps and exercise explicitly as before. However, now, sample_input will randomly sample all of the unspecified parameters for each of the 10 jobs.
Use custom parameter distributions#
sample_input is convenient, but sometimes you may want to sample parameters in particular ways:
job_params = [sample_input(
sesh=sesh,
num_reps=1,
exercise=random.choice(["UPPERCUT-LEFT", "UPPERCUT-RIGHT"]),
scene=random.choice(["LIVINGROOM_1", "BEDROOM_2"]),
lighting_power=random.uniform(10.0, 100.0),
) for _ in range(10)
]
The custom sampling strategies explicitly defined are different from what sample_input will do by default. We’re still using sample_input to randomly sample all other unspecified parameters.
Finally, visualizing the distribution of job parameters can be helpful to make sure you’ve crafted the right batch before committing to submission:
visualize_job_params(job_params)
For more information about parameter sampling, see the Infinity Core Session documentation.
Synthetic Data Output#
A major strength of synthetic data is the ability to provide rich, perfect labels. In the case of our computer vision-oriented VisionFit generator, we provide numerous scene-, frame-, and instance-level annotations along with various segmentation annotations.